[Ghost] 블로그 연관포스트 기능 추가하기
![[Ghost] 블로그 연관포스트 기능 추가하기](https://c1.staticflickr.com/6/5601/14986371364_0db6f0aeb2.jpg)
ghost 블로그 툴을 선택해서 사용한지도 꽤 되어 가는데, 마크다운(markdown)을 이용한 글쓰기 툴을 제공한다는 점 그리고 서비스와 설치형이 모두 있다는 점에서 선택했지만, 기존에 사용했던 티스토리, 워드프레스에 비해서 몇몇 기능이 없는 것은 사실이다. 카테고리를 지정하거나, 사이드바에 있는 다양한 기능들은 사실상 ghost 블로그에서는 찾아 보긴 힘들다.(서비스 형에서는 어떤지 모르겠다.)
이번에 블로그에 추가한 기능은 해당 포스트와 연관이 있는 글을 찾아서 사이드바에 5개를 보여주는 기능이다. 일명 연관 포스트 기능. 만들계 된 계기는 대부분 검색을 통해서 들어 올텐데 관련된 다른 포스트를 볼 수 있다면 좋지 않을까 하는 막연한 생각에 시작하게 되었다.
1. 데이터베이스 파악하기
ghost 설치형에서는 많은 데이터베이스를 지원해주고 있지만, 개인적으로 sqlite3를 선호한다. 파일의 형태로 나중에 백업시에도 유용하다고 생각해서 애초에 설치할 때 sqlite3를 선택해서 사용했다. 맥(mac)에서 DB Browser for SQLite 툴을 이용해서 로컬로 가져온 블로그 DB를 열어서 확인해 보았다. 어떤 식으로 구현을 할까 생각하기 전에 일단 어떤 정보들을 ghost에서 어떻게 저장하고 있는지에 대한 파악이 필요했다.
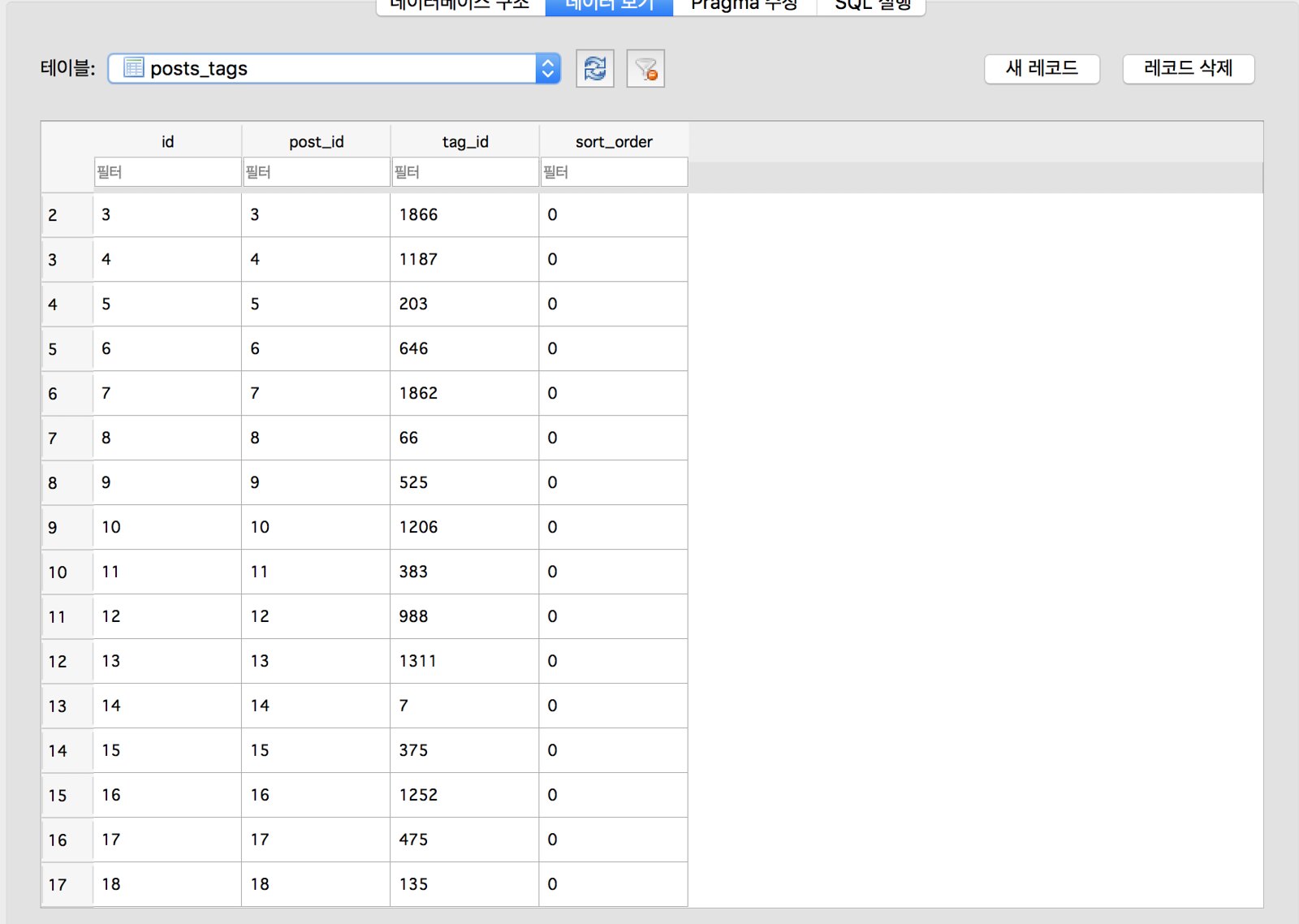
posts, tags 그리고 posts__tags 이렇게 3개의 테이블이 연관이 있는데 posts__tags는 하나의 포스트와 여러개의 태그의 관계를 기록하는 관계 테이블이다. posts 에는 포스트 관련 정보만 들어있고, tags 에는 태그 관련 정보만 들어있다.
2. 설계
거창하게 설계라고 할 것 까진 없지만 굳이 쓰자면 이렇다. 연관 포스트 기능을 어떻게 만들까? 라고 생각했을때 처음 생각한것은 현재 사용자가 보는 포스트에 대한 특징 값을 가지고 다른 블로그 DB에 있는 특징값(features)들을 가지고 매칭해서 가져오자는 것이었다. 막연하지만, 그렇게 가야 겠다는 생각을 했다.
그리고 두가지 방안이 있었다.
하나는 블로그의 태그를 이용하는 방법,
다른 하나는 본문의 형태소 분석 결과를 이용해서 매칭을 하는 방법.
결과적으로는 태그를 이용하는 방법으로 현재 구현이 되어 있다.
그 방법을 선택한 몇 가지 이유를 들자면:
-
속도에 대한 측면 : 사용자가 보는 글과 전체 글에 대한 형태소 분석을 실시간으로 할 수 있을까? 하는 부분에서 망설여 졌다. 물론 블로그DB에 형태소분석 결과를 미리 분석해서 넣어두는 방식도 있는데 이 부분은 DB구조 변경으로 인한 차후 ghost 블로그의 업그레이드시의 문제가 될 수 있을것 같았다.
-
정확성에 대한 측면 : 확실히 형태소 분석을 이용한 방법이 정확성을 높을 수 있다고 생각하지만, 태그를 이용해서 구현한 경우 정확성에 대한 부분이 너무 떨어지지 않는다면 괜찮다고 생각했다. 약간 애매한 기준이긴 하지만, 태그매칭 방식이 문제가 있으면 차후 형태소 분석으로 하자라는 생각을 하게 되었다.
태그 방식으로 결정을 하고 그 다음은 어떤 식으로 구현할 것인가, 아니 좀 더 상세하게 애기하자면 ghost 안에 구현을 할 것인가 아니면 하나의 서버를 따로 띄워서 API 형식으로 제공할 것인가 하는 부분에서 고민이 있었다. ghost 안에 두고 모듈처럼 호출해서 사용하는게 확실히 더 나은 방법이다. 그렇지만, node.js 그리고 ghost 자체 구조를 파악해야 하는 부분이 약간 부담스러웠고, 빨리 구현하고 싶은 마음에 자신있는 python-flask 로 구현된 기존의 API 서버에 하나 만들어서 사용하기로 했다.
3. 구현
구현 자체는 어렵지 않았는데, API 요청이 들어오면, 서버에 있는 sqlite3 DB에서 전체 포스트들의 태그들을 가져와서 매칭하는 방식으로 구현했다. 처음에는 API 상에서 post_id 같은 값을 받아서 현재 포스트에 대한 태그를 가져오려고 했지만, 알아내기가 쉽지 않아서 tags(쉼표로 구분)를 받는 방식으로 변경을 했다. API 함수에서 받은 tags와 블로그 DB(sqlite)에서 전체태그를 가져와서 매칭을 한 후, 매칭된 태그의 Post 들을 찾고, 해당 Post 를 발견되는 카운트를 기록을 하고 해당 매칭카운트를 기준으로 내림차순 정렬을 해서 API JSON 응답으로 내보내는 식으로 구현했다. 굳이 소스코드는 넣지 않아도 쉽게 이해할 수 있을것이다.
//응답 json
{
"data": [
{
"link": "https://ash84.net/2014/12/18/flask-logger-decorator",
"title": "flask logger decorator(\ub370\ucf54\ub808\uc774\ud130)\uc640 \ud568\uaed8 \uc0ac\uc6a9\ud558\uae30"
},
{
"link": "https://ash84.net/2013/08/08/flask-helloworldpy",
"title": "(flask) helloworld.py"
},
{
"link": "https://ash84.net/2013/09/06/flask-http-get-url--ec-b2-98-eb-a6-ac",
"title": "(flask) http get url \ucc98\ub9ac"
},
{
"link": "https://ash84.net/2013/10/06/flask-static--ed-8c-8c-ec-9d-bc--ec-a7-80-ec-a0-95",
"title": "(flask) static \ud30c\uc77c \uc9c0\uc815"
},
{
"link": "https://ash84.net/2013/10/23/flask-tornado--ec-84-9c-eb-b2-84--ec-a0-81-ec-9a-a9",
"title": "(flask) tornado \uc11c\ubc84 \uc801\uc6a9"
}
],
"meta": {
"code": 200,
"message": null
}
}
링크 주소를 만들어내는 과정에서 현재 블로그의 경우 모든 글의 URL이 날짜기반으로 되어 있기 때문에 post 의 published_at 날짜와 slug 값을 조합해서 만들어 냈다. 이 부분은 각 블로그마다 조금 다를수 있을 것 같다.
url = '/'.join([BASE_URL, str(published_at.year), '{:02d}'.format(published_at.month), '{:02d}'.format(published_at.day), slug])
블로그의 프론트단에서는 해당 API를 호출하는데 결과가 없는 경우, Related Posts 부분을 숨기고 결과가 있는 경우에만 주고 있다. 포스트가 아닌 주소를 바로 치고 들어간 경우(일종의 블로그 홈인데)에는 포스트가 없이 목록만 있기 때문에 이 경우에도 숨기고 보여주지 않는다.
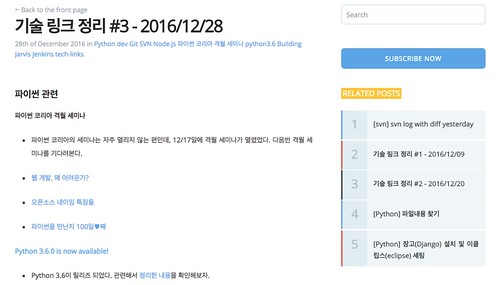
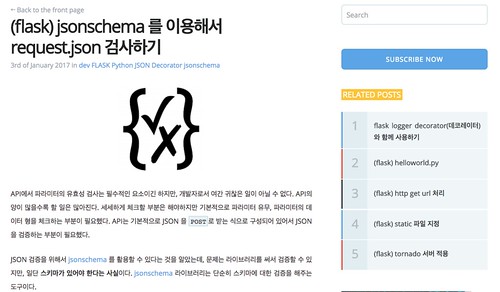
4. 개선 및 기능 추가 포인트
개발하면서도 좀 더 개선할 부분이 있지 않을까 하는 생각이 들었고, 몇 가지를 적어보자면 아래와 같다.
-
평가의 문제 : 하나의 포스트와 다른 하나의 포스트가 연관이 있다는 것을 어떻게 검증할 것인가? 만들고 나니 이 질문에 대한 대답이 더 먼저 선행되어야 했지 않았을까 하는 생각이 든다. 뭔가 평가나 테스트 방법이 있어야 알고리즘이나 방식을 개선했을때의 제대로된 평가가 이루어질 것 같다.
-
정확성에 대한 개선 : 형태소 분석을 이용한 방법에 대해서 역시 고민을 하고 있다. 확실히 정확성에 대한 부분을 비교해서 검증해 보고 싶다는 생각도 있고, 두 개의 방식을 적절히 섞어 보면 어떨까 싶다.
-
블로그 홈에서 어떻게 보여줄까? : 연관포스트와는 관련이 없지만, 인기포스트를 보여준다거나 하는 것도 좋을것 같다는 생각이 든다.(다음엔 인기포스트?)
정리
심심해서 만들어본것인데 생각보다 재밌었던것 같다. 여전히 아쉬움은 남는다. 몇몇 포스트들의 연관글을 보면 왜 이게 나왔지 싶은 것들도 있다. 한동안 운영해보고 질리면 좀 더 업그레이드 해 보고 싶은 생각은 있다. 이 글을 마무리 하는 시점에서 이 글에 어떤 태그를 달아야 할지 고민이 된다.